The Pick
Make disciplined betting feel effortless through conversational intelligence.
A sports-betting product I built and run on my own. Over three years I built three workstreams: an autoresearch engine that scores forecast quality and market value as separate contracts, a consumer chat on iOS and the web that mirrors ChatGPT's interaction model, and Sharp Shell, Claude Code for sports betting research.

From a 2024 Telegram broadcast to an engine that runs itself.
I started The Pick in 2024. The trust problem in the public picks market was measurement: plenty of opinions, paid plays, and AI-written rationales, but no clear way to separate calibrated probability from a good market price. I wanted a product I could trust enough to bet from, with the reasoning visible, the track record published, and the interface designed for bettors who care about discipline.
The first version was a Perplexity-driven prediction system I ran through a Telegram app during the 2024 NFL season, publishing the day's top five picks. The methodology held up, the channel grew through word of mouth, and the shape of a real product became visible. In 2025 I built it out with agentic coding tools: the web product moved through the year, the iOS app shipped by year-end, and the picks moved from a daily Telegram broadcast into a consumer chat that mirrored the interaction model people were already using with ChatGPT.
In 2026 the prediction layer became autonomous. The autoresearch engine now runs end to end, with a forecast layer that scores probability quality on odds-free metrics and a pricing layer that scores market value on EV, ROI, and closing-line value. Sharp Shell shipped alongside it as Claude Code for sports betting research, opening the same toolset to power users in a terminal-resident agent.

Two layers, scored differently.
A pick can be right for the wrong reason. The probability model can be calibrated while the market price is bad, or the market can be mispriced while the model is noisy. If both questions collapse into one ROI number, the track record can't tell which side of the trade is actually working.
The autoresearch engine separates them by construction. A forecast layer takes calibrated probabilities and grades them against held-out outcomes with odds-free metrics: Brier and log-loss improvement against the sport's published baseline, reliability buckets, and minimum sample support per market. A pricing layer takes those same probabilities, joins them to live quotes, and grades the resulting paper bets with realised ROI, expected value, and closing-line value where the venue exposes it. A candidate can graduate to the forecast contract on probability quality alone. Pricing promotion only fires when a forecast artifact is paired with enough settled paper bets at acceptable EV. A surviving forecast can sit unpriced when the venue isn't quoting, and a pricing policy can be retired without invalidating the forecast underneath it.

What the engine reads.
Each row in the matrix is a single (event, player, market family) triple. The strategy factory consumes a typed feature bundle drawn from rolling player-event windows: a baseline probability from the sport's published model, strokes-gained-style form signals (weighted recent, long-window trend, variance), a course-fit delta against the player's own baseline, and a panel of placement-rate and round-quality histories.
Every feature is a dbt-built view with an as-of guard, a constraint that says a feature for event X cannot see a round that started after event X. No leakage from the future, ever. The shape generalises across sports: a typed feature bundle encodes whatever the candidate is being asked to weight, and the sport's published baseline carries the rest. The scoring math is golf's reference; the artifact lifecycle and contracts travel.
How a row becomes a probability.
Start with the sport's baseline probability (DataGolf for golf, the equivalent for the others) translated into log-odds, the space where adding numbers is meaningful. Add weight × normalised-feature for each feature the candidate uses. Translate back to a raw probability. Pass through the candidate's calibration map (probability buckets with Beta/binomial reliability intervals over the validation split) to get the calibrated probability the rest of the pipeline reads from.
How a candidate clears each layer.
Each candidate is graded by a walk-forward event split (train, validation, test, all chronological, no random shuffle) and run head-to-head against an empty-weights baseline. Forecast gates check probability quality on odds-free metrics: Brier and log-loss improvement against the baseline, calibration error per reliability bucket, minimum settled-event support, and concentration limits across event, player, and market family. Pricing gates fire only on forecast artifacts that already cleared the forecast contract: positive validation and test ROI at a 1-unit fixed stake, sufficient settled paper-bet count, drawdown bounds, and closing-line-value diagnostics where the venue exposes the closing price.
A non-empty blocker list fails the run and is recorded with the named reason. Every run writes its experiment fingerprint into a shared memory before the next research cycle starts, so duplicate experiments skip at the hash check and graduated artifacts are reproducible row by row from the artifact key, dataset hash, and prediction-input snapshot.
How the engine grades itself against settled outcomes.
When a calibrated probability clears its candidate's pricing threshold, the row is written to a priced-decisions table. A canonical prediction set selects the active bets per event, stakes are sized, the bet enters a ledger, and append-only settlement events record the outcome. Aggregate performance, including realised ROI and closing-line value where the venue exposes it, feeds straight back into the experiment memory the next research cycle reads from. Every sport runs its own auto-research loop on this shape, and every promoted artifact emits decisions through one Rust runtime and a PMXT execution spine that fronts Kalshi and Polymarket.
Where surviving models find their edge.
One pattern from running the engine has been a surprise. The models that survive promotion behave as directional edge detectors. They outperform consistently on one side of the market (wherever a specific kind of mispricing concentrates) and perform unremarkably on the opposite side.
The NBA spread model is the clearest example. Across three separate seasons, picks on the away (underdog) side hit at 68 to 70 percent and run above 30 percent ROI. Picks on the home (favorite) side run at roughly zero. The blended model averages the two and looks unremarkable. The directional one is among the strongest in the portfolio.
The same shape repeats on player props, moneylines, and golf top-10 finish markets. The artifact promoted into production is three things together: a model, a profitable side filter, and a calibrated confidence band. Every surface downstream reads from that artifact.
Picks the bettor can act on.
A bettor at a sportsbook is doing five things at once: tracking the line, reading injury news, checking calibration, comparing books, deciding the stake. The product had to reduce that load at the moment of decision, not send the user into a feed, a stat dashboard, and a separate chat.
The engine graduates picks; the chat presents them. The interaction model mirrors ChatGPT: same threading, same streaming, same response animations, the same affordances for follow-ups, regenerations, copy, and share. A user arriving from any modern AI chat product is operating the surface from the first turn.
The shell stays out of the way.
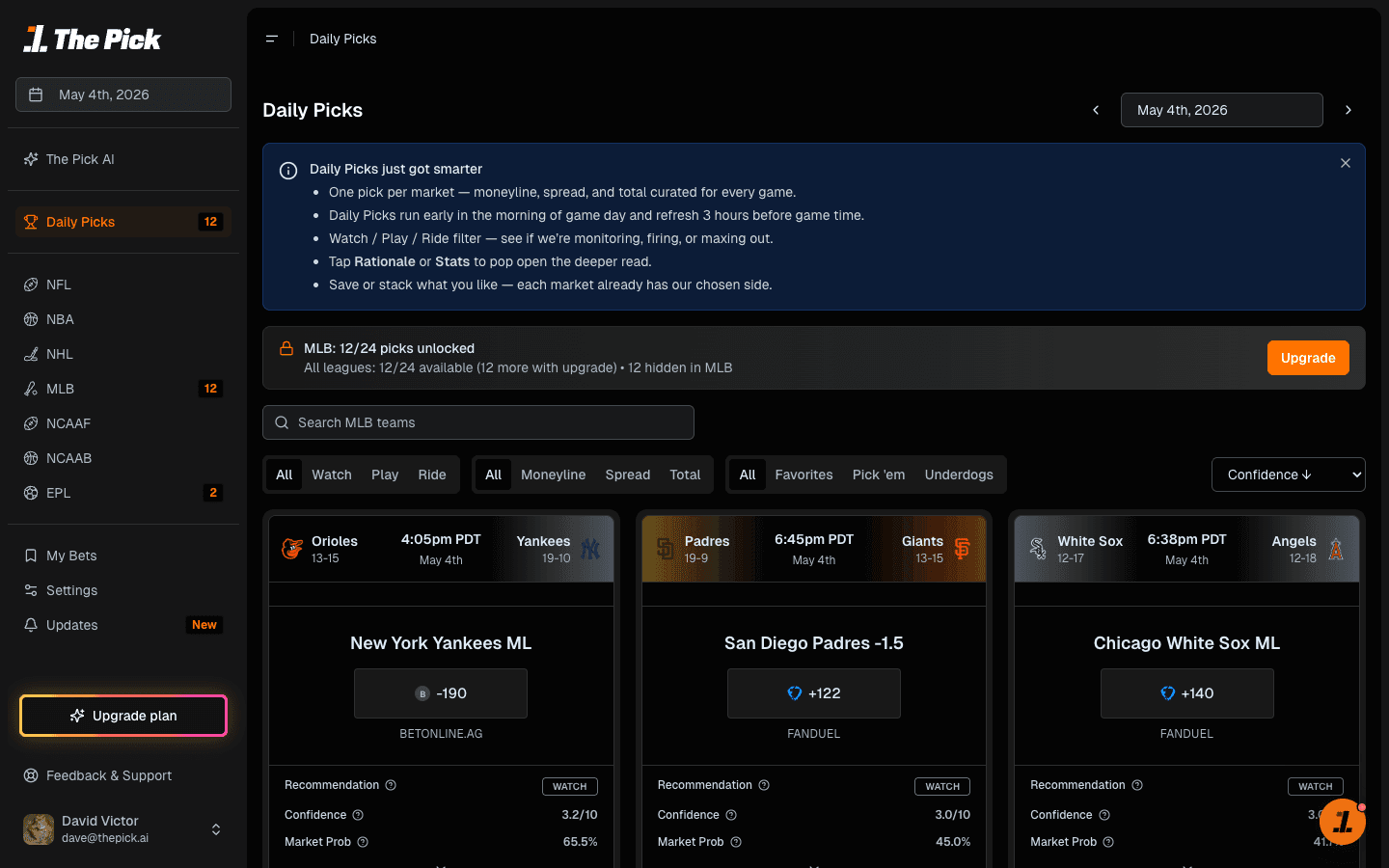
Claude Code for sports betting research.
The consumer chat is opinionated by design. It picks two cards a day and explains the call. Power-user bettors don't want curation. They want the toolset open, custom scans the chat doesn't surface, calibration sanity checks, fill simulation before the order goes in.
Sharp Shell is the third surface. A user installs it, drops in their API key, and gets a domain-specific sports-betting agent that lives in their terminal and over a messaging gateway. Persistent memory across sessions. Custom workflows composed from the same tools the consumer chat calls under the hood.
It's a programmable agent in a terminal that exposes the underlying model and the full toolset, with the user driving the depth of the analysis.
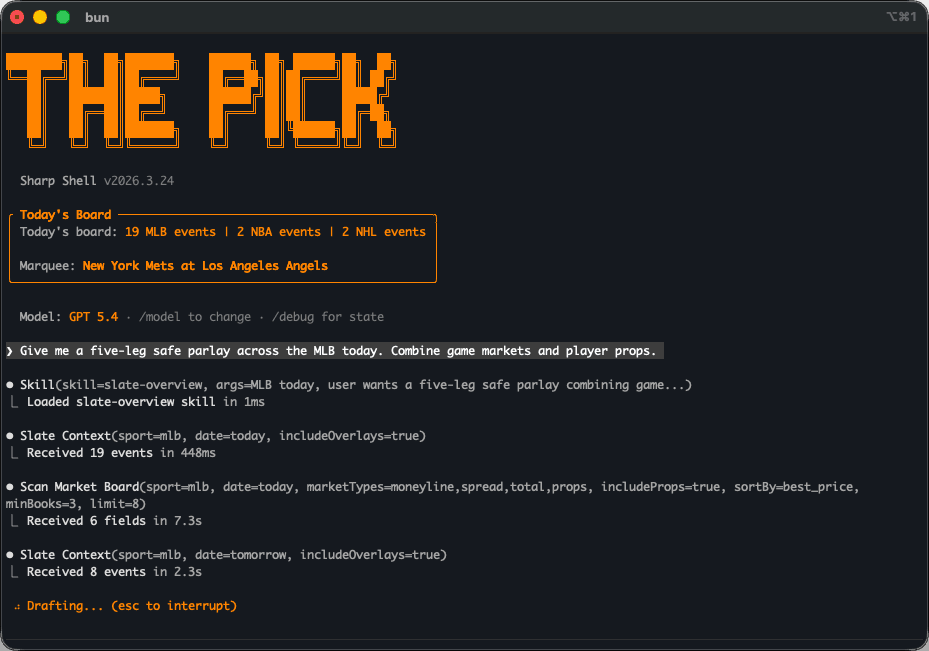
In private beta with the power-user cohort.
Sharp Shell is currently in private beta with the power-user cohort it was built for. The consumer chat is curated and opinionated. Sharp Shell exposes the full research toolset (feature lookups, market-price history, candidate scoring, calibration introspection, fill simulation) for the user to drive directly. Both surfaces read from the same artifacts and the same memory, so a candidate the engine promotes is visible to both products on the next cycle, with no separate publishing step.
What's running.
The consumer chat on iOS and the web has 500 paying subscribers and a 30 percent daily active rate. The initial subscriber base came from the early Telegram app I ran during the 2024 NFL season; growth has been one hundred percent organic since, with no marketing spend. The autoresearch engine covers every major American sport including golf, with promoted models tracked through a settled paper-bet ledger before they enter the production portfolio. The strongest current artifact is the NBA spread on the away (underdog) side at above 30 percent ROI across three separate seasons, with forecast quality scored separately from pricing performance. Sharp Shell shipped to the power-user cohort as Claude Code for sports betting research, and decisions from every sport's auto-research loop flow through one Rust runtime and a PMXT execution spine that fronts Kalshi and Polymarket.